Reading on Google?
Add Tampa Web Technologies as a preferred source to see more of our AEO and SEO research in your Top Stories.
AEO · GEO · Google Search Architecture
What Google’s Fan-Out Architecture Means for Your AI Citation Strategy
A Google search engineer just explained, on the record, how AI Overviews actually retrieves content. The mechanism validates exactly why thin pages get filtered out — and why owned technical depth survives.
The AEO conversation has spent a lot of time on outcomes — which pages get cited, which engines favor owned content, how citation share breaks down by vertical. Less time has been spent on the mechanism. How does Google’s AI Overviews actually decide what it reads?
In May 2026, Google’s Search Off the Record podcast published Episode 109, “How Search Is Changing.” The guest was Nikola Todorovic, who leads SafeSearch engineering at Google’s Zurich office and has been part of Google’s search organization for fifteen years. In the conversation, he explained, clearly and on the record, how AI Overviews processes a query — including a mechanic called fan-out that gets very little coverage outside of Google’s own engineering circles.
The fan-out explanation has direct implications for AEO strategy. It is not abstract. It tells you specifically why certain pages survive AI retrieval filtering and why others do not.
The fan-out mechanic, explained by Google
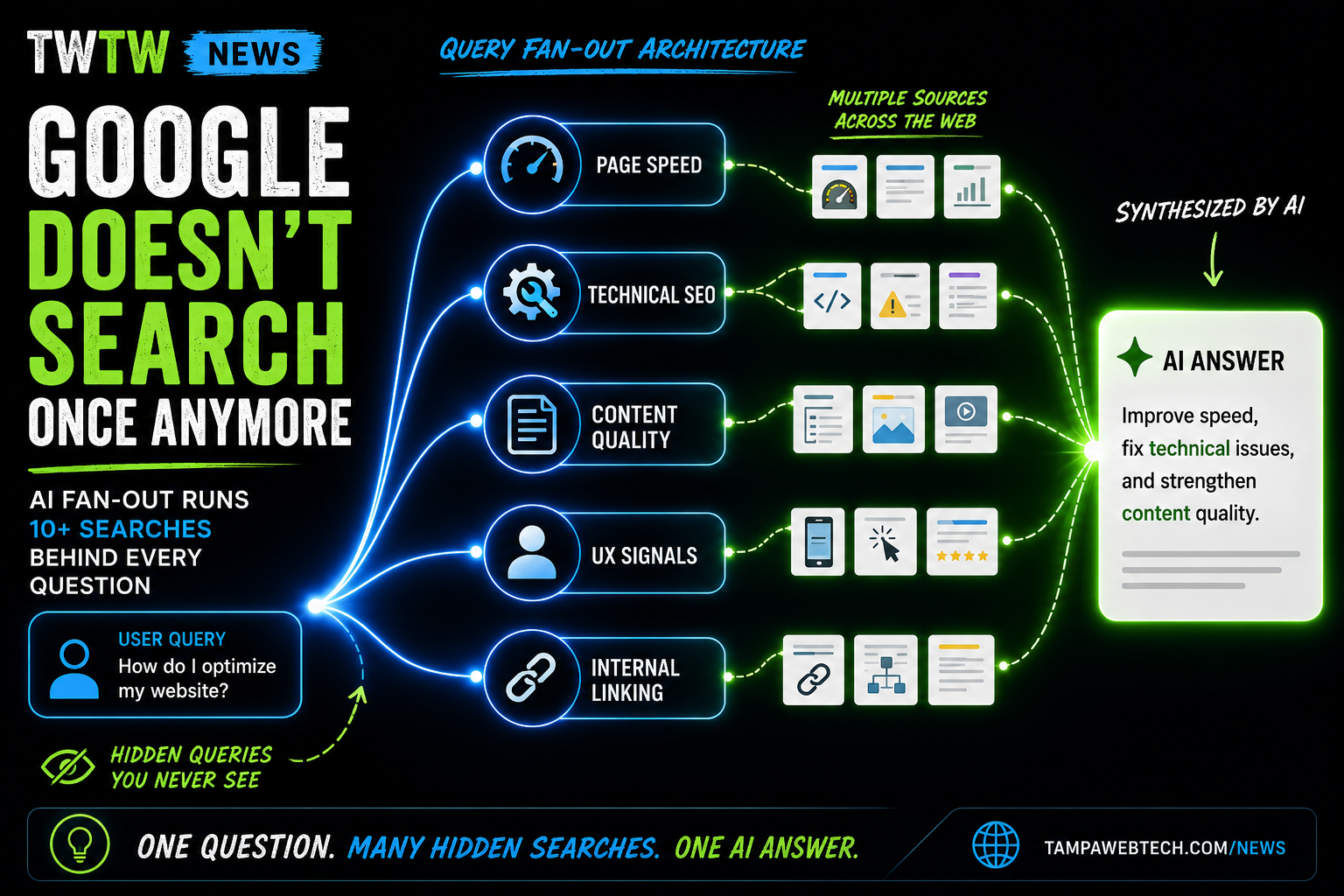
Here is what Todorovic described. When a user submits a query to Google’s AI Overviews, the system does not run a single retrieval against that exact query. It identifies additional related sub-queries that could yield results relevant to the original request. It then fires those sub-queries in parallel. All of the retrieved content comes back and AI Overviews synthesizes from across those results to produce the final summary.
“A fan out is when you have your own search query, but then we might identify some additional search query that will yield the results that can be relevant for your original search query as well. And then we can fork and in parallel do the retrieval for multiple search queries.”
— Nikola Todorovic, SafeSearch Engineering Lead, Google Zurich · Search Off the Record, Episode 109The practical result: a single user query is not a single retrieval event. It is several. Each sub-query runs against Google’s standard ranking and indexing infrastructure — the same systems that power organic search. AI Overviews then operates as a synthesis layer on top of whatever those retrievals return.
Todorovic was clear that the underlying retrieval and ranking in AI Overviews is “old school” — the same indexing and ranking systems that have always existed. The AI component is specifically the synthesis step: combining what it finds across those pages into a coherent response. The retrieval filter is the existing search stack. The AI layer does not read the broader web; it reads what the retrieval layer surfaces.
This matters because it means AI Overviews citation behavior is not arbitrary. It is constrained by the same signals Google’s ranking infrastructure has always used — with an additional layer of extraction quality on top.
Why thin pages get filtered out before the AI sees them
The fan-out architecture creates a two-stage filtering problem for any page trying to earn an AI citation.
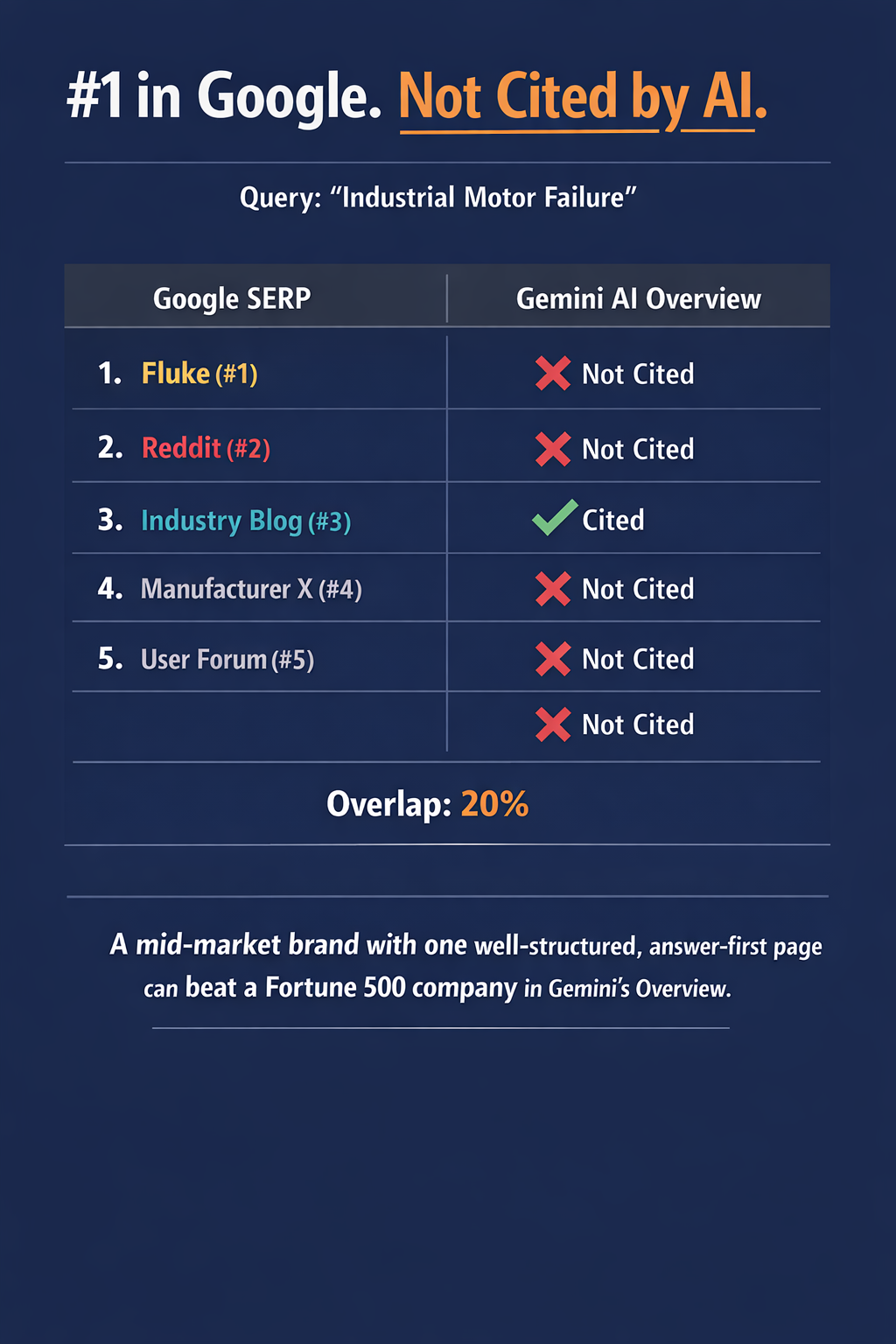
Stage one: the page has to survive Google’s standard ranking retrieval for not just the primary query, but potentially several sub-queries generated from it. A page that ranks marginally for the head term may not surface at all for the more specific sub-queries the fan-out generates.
Stage two: once retrieved, the AI synthesis layer has to be able to extract something useful from the page. Todorovic described AI Overviews as operating on “snippets, the titles, and additional context it can get out of those pages.” That is the synthesis layer working with what it can actually read — not with the full page, but with extractable content.
Pages that survive both stages
Deep owned content with clear heading structure, direct answers in early content, schema markup, and strong topical alignment to the specific sub-queries the fan-out is likely to generate.
Pages filtered at stage one or two
Thin content that ranks on domain authority alone, pages without extractable structure, and broadly optimized content that does not align tightly enough to the sub-query variants a fan-out produces.
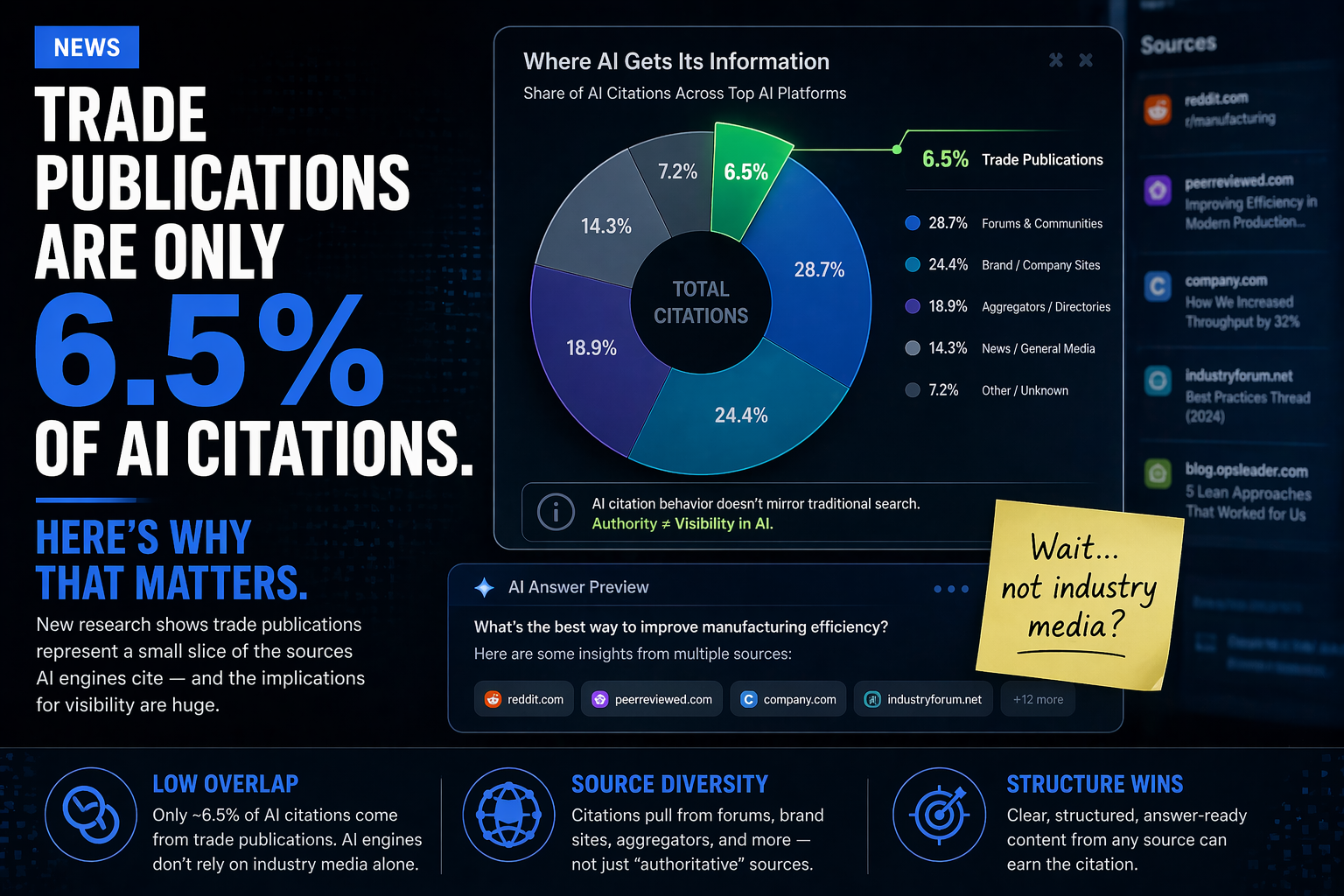
This is consistent with what our 550-citation B2B industrial study found: owned content with high Page Structure Scores dominated citation share at 48.3%, while trade publications — typically well-ranked in organic search — came in at only 6.5% of citations with the lowest mean PSS of any ownership type. Domain authority is getting pages retrieved. Extraction quality is determining which ones get cited.
Longer queries generate more sub-queries — and more chances to be filtered
Todorovic noted a second finding from Google’s internal data that compounds the fan-out dynamic. User query length is increasing. More people are typing longer, more detailed prompts into Google as they realize AI features can handle them.
A longer query gives the fan-out system more material to work with. It can identify more directions, generate more sub-queries, and retrieve from more angles. For a brand with deep owned content organized around specific sub-topics, this is an opportunity — more sub-queries means more chances for relevant pages to surface. For a brand with thin category-level content, longer queries generate sub-queries that the thin content cannot answer, and those pages never enter the synthesis pool.
The implication for content architecture: organizing around specific sub-topics, use cases, or specifications is not just good SEO practice. It is directly aligned with how fan-out generates sub-queries and what the AI synthesis layer can extract when it finds those pages.
The five PSS pillars map directly to what fan-out retrieval rewards
The Page Structure Score rubric used in our B2B industrial citation study was developed before this Google explanation was available. The fan-out architecture Todorovic described validates why each pillar matters at the mechanism level.
| PSS Pillar | Why it matters in a fan-out system |
|---|---|
| Answer extraction | The synthesis layer reads snippets and early content. If the answer isn’t in the first extractable content block, AI Overviews may not surface it even if the page was retrieved. |
| Content formatting | Heading structure and list organization give the synthesis layer clear signals about what each section answers — critical when sub-queries are more specific than the original prompt. |
| Technical readability | Pages that render poorly or have heavy JavaScript-dependent content may be retrieved but fail at the extraction stage. The synthesis layer works with what it can actually read. |
| Schema markup | Structured data provides unambiguous signals about page type and content classification — helping the retrieval system match pages to sub-queries accurately. |
| Topical alignment | Fan-out generates sub-queries from the original prompt. Content that covers specific sub-topics rather than broad categories is more likely to align to one or more of those sub-queries. |
The mean PSS across all 547 citations in the study was 32–35 depending on engine. Pages that earned citations without strong PSS tended to be dominant brands with no real competition in the query set — where the retrieval filter had few alternatives. For competitive verticals, higher PSS correlated with citation presence across multiple engines.
AI Overviews vs. AI mode — a different retrieval posture
Todorovic drew a distinction between AI Overviews and Google’s newer AI mode that matters for AEO planning. AI Overviews is the fan-out system on top of standard search — retrieval first, synthesis second. AI mode is described as having “a bigger platform for its own” — it still uses Google’s search infrastructure and still produces citations, but it has more autonomy and is designed for longer multi-turn conversations.
AI Overviews
Fan-out from standard search. Retrieval runs through existing ranking infrastructure. Synthesis layer operates in a constrained space on top of those results. Cited sources are largely determined by what organic retrieval surfaces first.
AI mode
Still search-based with fan-out and linked citations, but with a larger autonomous platform. Designed for multi-turn conversation. Todorovic describes it as “no longer in isolation” — it has more surface area to operate across.
For B2B industrial brands, the near-term priority is AI Overviews, because it touches the highest volume of queries and draws from the same retrieval system as organic search. The content architecture that improves AI Overviews citation share — deep owned content, strong PSS, tight topical alignment — also builds the foundation for AI mode as it scales.
The practical checklist from this architecture
The fan-out mechanic is not a reason to chase sub-keywords as individual targets. It is a reason to build content with enough depth and specificity that sub-queries — wherever they land — find a page on your site that can answer them.
- Map your sub-topics, not just your head terms. For every primary category query your brand wants to own, identify the more specific questions that a fan-out is likely to generate. Build content that addresses each directly.
- Put the answer in the first extractable block. The synthesis layer reads snippets and early page content. If your answer is buried in paragraph seven, it may not reach the synthesis pool even if the page was retrieved.
- Structure matters more than word count. Clear heading hierarchy signals to both the retrieval and synthesis systems what each section covers. A well-structured 800-word page outperforms a poorly structured 3,000-word page in AI extraction.
- Schema closes the loop. Structured data — Article, Product, FAQ — gives the retrieval system unambiguous classification signals that help match your pages to the right sub-queries in the fan-out.
- Technical rendering is not optional. If your page requires JavaScript to display its primary content, the synthesis layer may retrieve a shell and extract nothing useful. Test for crawlable, rendered content.
Sources and methodology
Search Off the Record, Episode 109 — “How Search Is Changing”
Google’s Search Off the Record podcast, hosted by Martin Splitt (Developer Relations). Guest: Nikola Todorovic, SafeSearch Engineering Lead, Google Zurich. Published May 2026. The fan-out explanation, AI Overviews architecture description, query length finding, and AI mode distinction referenced in this article are drawn from that episode. All characterizations are paraphrased from the transcript; no extended quotes are reproduced.
Tampa Web Technologies 550-citation B2B industrial study
Queries were run across ChatGPT, Perplexity, and Gemini between late 2025 and early 2026. Each citation was classified by ownership type and scored against a five-factor Page Structure Score rubric measuring answer extraction, content formatting, technical readability, schema markup, and topical alignment. Sixteen B2B industrial verticals were included. The PSS correlations and ownership distribution figures cited in this article come from that dataset.
Limitations
The TWT study covers 550+ citations in B2B industrial verticals specifically. Findings should not be generalized to consumer, entertainment, or healthcare-consumer categories. PSS is a proprietary working rubric, not a peer-reviewed measure. The Google podcast episode reflects one engineer’s framing of AI Overviews architecture; Google does not publish a formal technical spec of the fan-out system for external use.
Audit your AI citation architecture
Tampa Web Technologies measures your real citation share across ChatGPT, Perplexity, and Gemini — and diagnoses exactly where your content is getting filtered before it reaches the synthesis layer.
Talk to Tampa Web TechnologiesDavid Chamberlain is a search strategist and founder of Tampa Web Technologies, where he focuses on the intersection of AI and search visibility. His work centers on Answer Engine Optimization (AEO), Generative Engine Optimization (GEO), and the structural changes reshaping how businesses appear in AI-driven results. David has 17 Years of Tech Experience.
He writes regularly on AI search updates, industry shifts, and the evolving dynamics of zero-click discovery, providing analysis designed for business leaders and technical teams.