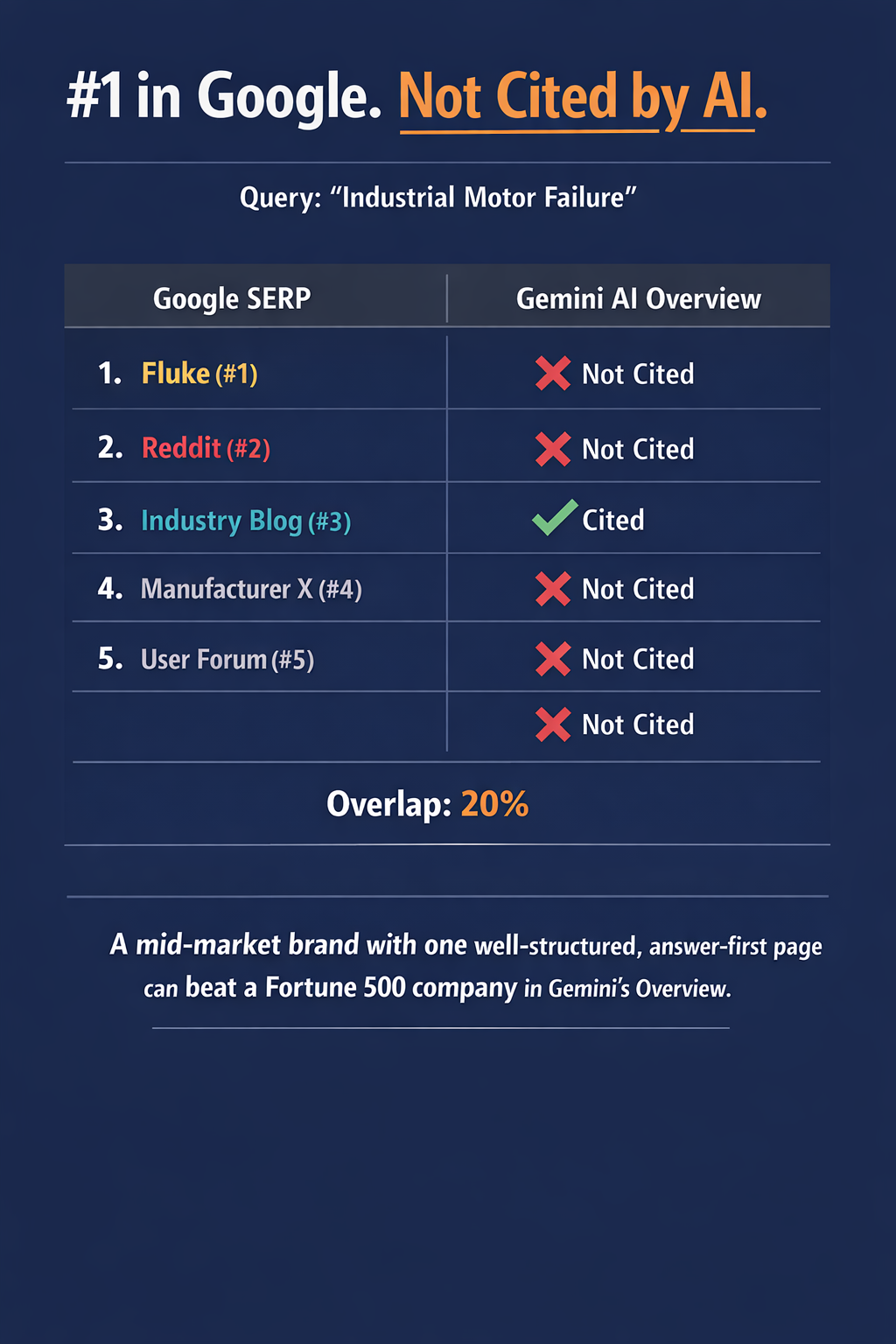
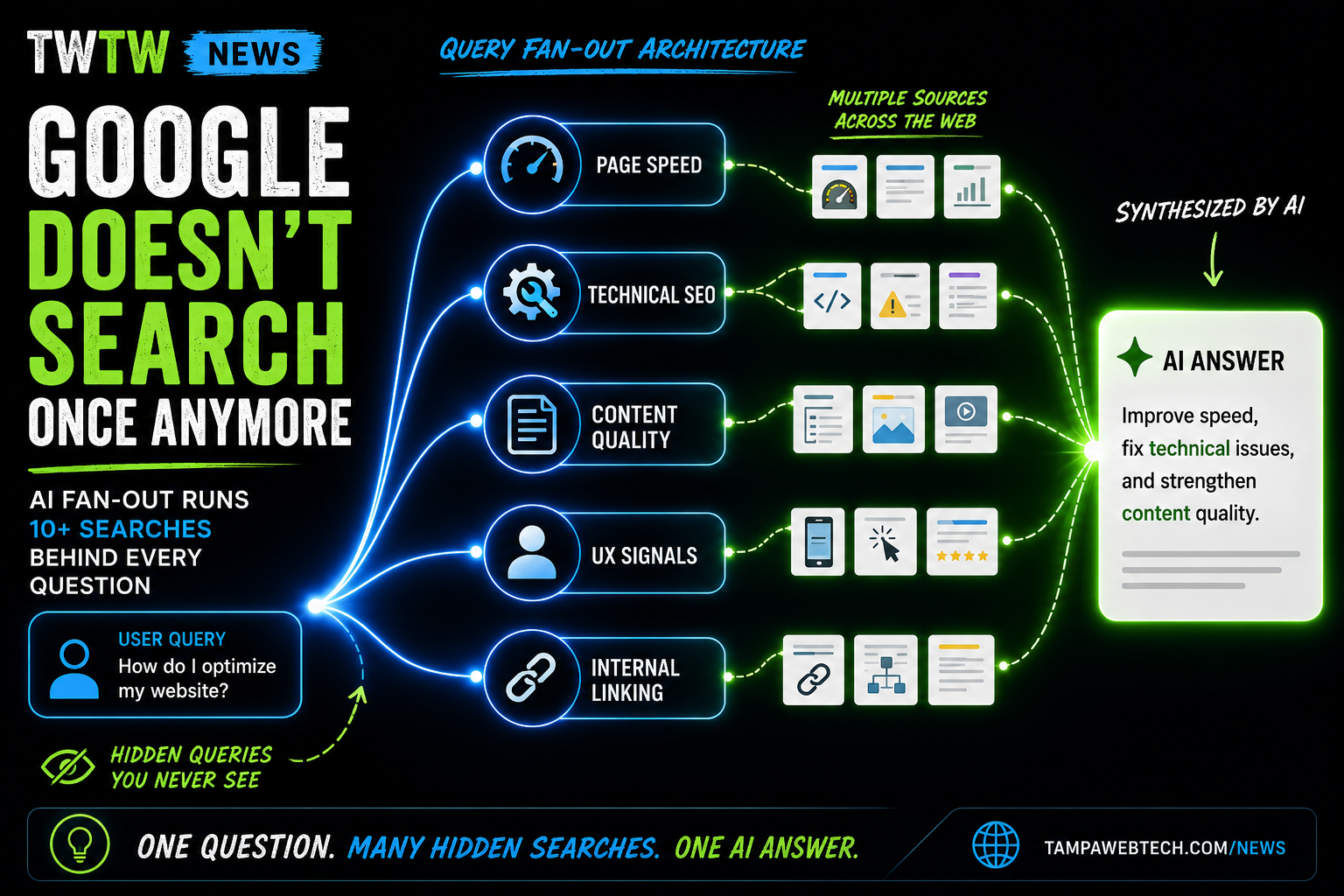
Reading on Google?
Add Tampa Web Technologies as a preferred source to see more of our AEO and SEO research in your Top Stories.
Latest in AI · April 2026
Two frontier models in eight days, and a federal AI framework on the table.
Anthropic shipped Claude Opus 4.7 on April 16. OpenAI shipped GPT-5.5 on April 23. Anthropic Labs unveiled Claude Design. The White House sent Congress a national AI legislative framework. If you operate a B2B business, this month changed your evaluation criteria, your procurement risk, and the platforms you should be testing against.
The release cadence used to be measured in months. It is now measured in days. That alone is the story.
Claude Opus 4.7: a quiet upgrade that hits where it matters
Anthropic released Claude Opus 4.7 on April 16, 2026, and the framing was unusually restrained for a frontier model launch. No “world-changing” language. No staged demo. Just a direct claim: it is meaningfully better than Opus 4.6 at the hardest software engineering work, with substantially improved vision and instruction following.
The numbers in the announcement are worth reading in full, but a few stood out. Replit reported the same output quality at lower cost. Cursor saw their internal benchmark jump from 58 percent on Opus 4.6 to over 70 percent on 4.7. Notion saw a 14 percent gain on multi-step workflows with one third the tool errors. XBOW, which runs autonomous penetration testing, watched a vision benchmark go from 54.5 percent to 98.5 percent — a step change rather than a refinement.
Two practical changes matter for anyone shipping content or running agentic workflows. First, Opus 4.7 takes instructions more literally than prior models. Prompts that worked through interpretive slack on 4.6 may now produce surprising results. Anthropic flagged this directly and recommended re-tuning. Second, the model accepts images at three times the prior resolution — up to roughly 3.75 megapixels — which opens up real document and diagram work that previously required workarounds.
Opus 4.7 also introduces a new xhigh effort level between high and max, giving developers a finer dial between reasoning depth and latency. Pricing is unchanged from 4.6: five dollars per million input tokens, twenty-five per million output.
GPT-5.5 lands seven days later
OpenAI released GPT-5.5 on April 23, 2026, seven days after Opus 4.7 and six weeks after GPT-5.4. The pace is the point. Greg Brockman called it “a faster, sharper thinker for fewer tokens” and described it as a step toward what OpenAI internally calls a “super app” — a unified surface combining ChatGPT, Codex, and an AI browser.
OpenAI's framing leans hard into agentic work. The pitch is that you can hand the model a messy, multi-part task and trust it to plan, use tools, check itself, and continue through ambiguity rather than waiting for step-by-step direction. The company highlighted gains in agentic coding, computer use, knowledge work, and early scientific research.
Two specifics matter. On Terminal-Bench 2.0, GPT-5.5 scored 82.7 percent against Opus 4.7's 69.4 percent — a real lead in command-line agentic work. On FrontierMath Tier 4, GPT-5.5 Pro scored 39.6 percent against Opus 4.7's 22.9 percent. Anthropic's lead in some benchmarks is now narrower than it was a week earlier, and OpenAI took a clear lead in others.
The pricing tradeoff is sharper than Anthropic's. GPT-5.5 API pricing is roughly twice GPT-5.4, though OpenAI argues token efficiency offsets that on real workloads. The honest answer for most operators is to measure on your own traffic before committing.
What the release pace actually means
If you are evaluating AI for a regulated or industrial workflow, the release cadence is now a procurement variable. A model you benchmarked in March is not the model that will be in production in June. That is not a reason to delay. It is a reason to build evaluation into your workflow rather than treat it as a one-time event.
The Bank of New York's CIO put it cleanly in coverage of the GPT-5.5 launch: for a regulated institution, the meaningful signal is hallucination resistance and response quality, not raw benchmark scores. That is the right frame. Your evaluation should be your data, your prompts, and your acceptance criteria — not a press release.
Claude Design enters the chat
Anthropic Labs is also walking through Claude Design, a new generative design surface that turns a prompt into a working, editable artifact. The walkthrough — led by Nate, a Member of Technical Staff who helped build it — frames it around three audiences: an engineer who has a working prototype that “looks rough” and wants to fix it without a designer, a product manager whose feature has been described in docs for a week and still is not landing, and a designer who needs to mock up three screens by tomorrow with no time to start from scratch.
What is actually shown is more ambitious than a slide generator. The example reel includes a fully interactive 3D terrain visualization with simplex-noise generation and live elevation readouts, a low-poly mid-century modern house with time-of-day lighting and weather simulation, a branded multi-day company offsite welcome guide built from a source document, a dark-themed proposal tracker with a radar pipeline visualization, a brand book with packaging and Instagram grid templates, and an “egg-shaped phone” prototype with a perspective-mapped screen overlay and an EGG TWEAKS panel. None of these are static mockups. They are interactive prototypes with a Tweaks/Knobs panel for live parameter editing.
The capability list at the end of the walkthrough is the operational story: hand off to Claude Code, import a local codebase, export editable .pptx, export standalone HTML, inline commenting, and live editing. That makes Claude Design less of a “design tool” and more of a prototype-to-production bridge. You can move from a prompt to a working artifact to a real codebase without breaking the chain.
The relevance for B2B operators is direct. The bottleneck on most marketing and sales work is not strategy — it is the gap between the brief and a working artifact someone can react to. A tool that produces editable, branded, interactive output from a document or a prompt collapses that gap from days to minutes. For agency and in-house teams, this is the surface to evaluate this quarter.
The federal framework: what to actually watch
On March 20, 2026, the Trump administration unveiled a National AI Legislative Framework laying out six policy objectives for Congress: protecting children online, strengthening communities and the grid, respecting intellectual property while preserving fair use for AI training, preventing political censorship in AI systems, accelerating innovation, and building an AI-ready workforce. The framework explicitly argues that a patchwork of conflicting state laws would undermine American competitiveness, and calls for uniform federal preemption.
The companion site at ai.gov frames the broader Action Plan around three pillars: accelerating innovation, building AI infrastructure, and leading international diplomacy and security. The plan has been moving since July 2025 — data center permitting, federal procurement reform, AI education executive orders — and the March framework is the legislative push to consolidate it.
For B2B operators, three things are worth watching. First, the IP and fair use question directly affects whether your published content can be cited, ingested, or transformed by AI systems — and what your recourse looks like if it is. Second, the data center and energy provisions affect compute costs and availability, which will eventually flow through to per-token pricing. Third, the preemption argument means state-level AI compliance work you are doing today may be reshaped by federal rules within 12 to 18 months. Build flexibility in.
What to do this week
If you have prompts or harnesses tuned for Opus 4.6, schedule time to re-test on 4.7. The literal-instruction-following change is real and will surface as silent regressions in workflows that depended on the older model's interpretive slack. If you run any computer-use or vision-heavy work, both new models are a meaningful upgrade and worth a real evaluation, not a quick test.
If you have a backlog of internal docs, briefs, or rough prototypes that need to become something a stakeholder can react to — pitch decks, brand guides, microsite mockups, a printable welcome guide for an event — spend an hour with Claude Design. The leverage is highest where you have a written artifact and need a visual one.
If you have content assets that depend on AI citation or ingestion — which is most B2B content strategy at this point — read the federal framework directly rather than relying on summaries. The IP language is the section that will shape how your work is treated by these systems, and the language is still being negotiated.
And if you have not benchmarked your own workflows against both Claude and GPT in the last 60 days, that is the single highest-leverage hour you can spend this month.
Frequently asked questions
What is Claude Design?
Claude Design is a generative design surface from Anthropic Labs that turns a prompt or source document into a working, editable artifact — ranging from interactive 3D scenes and dashboards to branded decks, brand books, mobile app prototypes, and printable welcome guides. It includes a Tweaks/Knobs panel for live parameter editing, inline commenting, exports to editable .pptx and standalone HTML, and direct handoff to Claude Code.
When did Claude Opus 4.7 and GPT-5.5 launch?
Anthropic released Claude Opus 4.7 on April 16, 2026. OpenAI released GPT-5.5 on April 23, 2026 — seven days later. Both launches followed a noticeably faster cadence than prior frontier model releases, with GPT-5.5 arriving roughly six weeks after GPT-5.4.
Which model is better for my business?
There is no single answer. On published benchmarks, GPT-5.5 leads Opus 4.7 in command-line agentic work and frontier mathematics, while Opus 4.7 leads in several enterprise document and reasoning evaluations. The right answer depends on your specific workflows. Benchmark both against your own data, prompts, and acceptance criteria before committing.
Did Opus 4.7 change anything that breaks existing prompts?
Yes. Opus 4.7 follows instructions more literally than Opus 4.6, which means prompts that worked through interpretive slack on the older model can produce unexpected results. Anthropic flagged this directly in the launch notes and recommended re-tuning prompts and harnesses. Opus 4.7 also uses an updated tokenizer, so the same input may map to roughly 1.0 to 1.35 times more tokens depending on content type.
What is the National AI Legislative Framework?
The framework is a set of legislative recommendations the Trump administration sent to Congress on March 20, 2026, covering six policy areas: child safety online, community and grid impact, intellectual property and fair use, free speech protections in AI systems, innovation acceleration, and workforce development. It explicitly argues against a patchwork of state laws and calls for uniform federal preemption. It is a framework, not law — the actual legislation is still being negotiated.
How should B2B operators respond to the release pace?
Treat model evaluation as an ongoing process rather than a one-time decision. Build a small, repeatable internal benchmark on your own workflows. Re-run it quarterly at minimum, and any time a major model is released. The goal is not to switch platforms with every release. The goal is to know what you are trading off when you do not.
Need help evaluating which AI fits your workflow?
Tampa Web Technologies builds evidence-first AEO and content strategies for industrial and B2B operators. We benchmark on your data, not press releases.
Get in touchDavid Chamberlain is a search strategist and founder of Tampa Web Technologies, where he focuses on the intersection of AI and search visibility. His work centers on Answer Engine Optimization (AEO), Generative Engine Optimization (GEO), and the structural changes reshaping how businesses appear in AI-driven results. David has 17 Years of Tech Experience.
He writes regularly on AI search updates, industry shifts, and the evolving dynamics of zero-click discovery, providing analysis designed for business leaders and technical teams.